Các bot thu thập dữ liệu như GPTBot của OpenAI, Google-Extended, hay ClaudeBot đang tích cực quét nội dung từ hàng triệu website để huấn luyện mô hình ngôn ngữ lớn. Tuy nhiên, không phải website nào cũng muốn chia sẻ nội dung của mình cho mục đích này. Bài viết hướng dẫn chi tiết cách bạn có thể kiểm soát quyền truy cập của các AI crawlers thông qua file robots.txt - một phương pháp đơn giản nhưng hiệu quả.
Tại Sao Cần Kiểm Soát AI Crawlers Trên Website?
Việc kiểm soát các bot AI không chỉ là vấn đề kỹ thuật mà còn liên quan trực tiếp đến quyền sở hữu trí tuệ và chiến lược kinh doanh của bạn. Khi các AI crawlers thu thập dữ liệu từ website, chúng sẽ sử dụng nội dung này để huấn luyện các mô hình AI mà sau đó có thể tạo ra câu trả lời tương tự, ảnh hưởng đến giá trị độc quyền của nội dung gốc.
Đối với các website hoạt động trong lĩnh vực nội dung chuyên sâu, việc bảo vệ tài sản trí tuệ trở nên quan trọng hơn bao giờ hết. Ngoài ra, các AI crawler có thể tạo ra lượng truy cập lớn, gây tăng tải cho server và ảnh hưởng đến hiệu suất website. Theo thống kê từ Cloudflare, một số website có thể nhận hàng nghìn request mỗi ngày chỉ từ các bot AI, chiếm tới 20-30% tổng lượng truy cập.

Về mặt pháp lý, việc thu thập dữ liệu bởi các bot AI đang là vấn đề tranh cãi. Nhiều quốc gia đang xem xét các quy định về quyền tác giả và sử dụng dữ liệu cho AI. Việc chủ động kiểm soát quyền truy cập giúp bạn tuân thủ các quy định này và có thêm quyền kiểm soát trong tương lai khi pháp luật cụ thể hơn.
Từ góc độ chiến lược SEO, việc cho phép hoặc chặn AI crawler cần được cân nhắc kỹ lưỡng. Trong khi chặn có thể bảo vệ nội dung, việc cho phép có thể giúp nội dung của bạn xuất hiện trong các câu trả lời AI, tạo thêm kênh tiếp cận người dùng. Do đó, quyết định này phụ thuộc vào mục tiêu kinh doanh cụ thể của từng website.
Danh Sách Các AI Crawlers Phổ Biến Cần Biết
Hiện tại, có nhiều công ty công nghệ lớn đã phát triển các bot riêng để thu thập dữ liệu huấn luyện AI. Mỗi bot có một user-agent riêng biệt mà bạn cần biết để cấu hình robots.txt chính xác. Dưới đây là danh sách chi tiết các bot phổ biến nhất:
| Tên Bot | User-Agent | Công Ty | Mục Đích |
|---|---|---|---|
| GPTBot | GPTBot | OpenAI | Thu thập dữ liệu cho GPT-4, GPT-5 |
| Google-Extended | Google-Extended | Huấn luyện Bard và các mô hình AI | |
| CCBot | CCBot | Common Crawl | Lưu trữ dữ liệu web công khai |
| ClaudeBot | ClaudeBot | Anthropic | Huấn luyện Claude AI |
| PerplexityBot | PerplexityBot | Perplexity AI | Tìm kiếm và trả lời câu hỏi |
Điểm quan trọng cần lưu ý là các bot này khác biệt với bot tìm kiếm truyền thống như Googlebot hay Bingbot. Trong khi bot tìm kiếm giúp website được index và hiển thị trên kết quả tìm kiếm, các AI crawler chỉ thu thập dữ liệu để huấn luyện mô hình mà không trực tiếp đóng góp vào SEO của bạn.
Một số bot có thể sử dụng nhiều user-agent khác nhau hoặc thay đổi theo thời gian. Ví dụ, OpenAI trước đây sử dụng bot không có tên cụ thể, nhưng từ tháng 8/2023 đã chính thức công bố GPTBot. Do đó, việc cập nhật danh sách bot thường xuyên là cần thiết để đảm bảo hiệu quả kiểm soát.
Cách Chặn GPTBot Bằng Robots.txt
File robots.txt là công cụ chuẩn để giao tiếp với các bot và crawler về quyền truy cập vào website. File này phải được đặt ở thư mục gốc của website và có thể truy cập qua đường dẫn yourdomain.com/robots.txt. Dưới đây là hướng dẫn từng bước để thiết lập chặn AI crawler hiệu quả.
- Các bạn có thể tham khảo thêm tài liệu về file robots.txt do chính Google cung cấp tại đây.
Bước 1: Truy Cập File Robots.txt Hiện Tại
Đầu tiên, bạn cần kiểm tra xem website đã có file robots.txt chưa bằng cách truy cập https://congcuseoai.com/robots.txt. Nếu file đã tồn tại, bạn sẽ thấy các quy tắc hiện có. Nếu chưa có, bạn cần tạo file mới. Trên WordPress, bạn có thể sử dụng plugin như Yoast SEO hoặc Rank Math để quản lý file này dễ dàng hơn.
Bước 2: Cấu hình chặn AI BOT
Chặn Hoàn Toàn Các AI Crawlers
Để chặn toàn bộ website khỏi các bot AI, thêm các dòng sau vào file robots.txt:
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
Cú pháp Disallow: / có nghĩa là chặn truy cập vào tất cả các trang trên website. Lưu ý rằng mỗi bot cần được khai báo riêng với dòng User-agent riêng biệt.
Chặn Chọn Lọc Theo Thư Mục
Nếu bạn chỉ muốn bảo vệ một số phần cụ thể của website, ví dụ như blog hoặc tài liệu nội bộ, bạn có thể sử dụng cấu hình chi tiết hơn:
User-agent: GPTBot
Disallow: /blog/
Disallow: /tai-lieu/
Disallow: /admin/
User-agent: Google-Extended
Disallow: /blog/
Disallow: /tai-lieu/
Cách này cho phép các bot AI vẫn truy cập các phần khác của website nhưng không thể thu thập nội dung từ các thư mục được chỉ định. Điều này hữu ích khi bạn muốn bảo vệ nội dung chất lượng cao nhưng vẫn cho phép bot quét các trang thông tin chung.
Kết Hợp Cho Phép và Chặn
Trong một số trường hợp, bạn muốn kiểm soát chi tiết hơn bằng cách kết hợp cả Allow và Disallow:
User-agent: GPTBot
Allow: /gioi-thieu/
Disallow: /blog/
Disallow: /
Lưu ý rằng thứ tự các quy tắc quan trọng. Bot sẽ áp dụng quy tắc cụ thể nhất trước. Trong ví dụ trên, thư mục /gioi-thieu/ được cho phép mặc dù có quy tắc Disallow: / chặn toàn bộ website.
Bước 3: Lưu và Triển Khai
Sau khi chỉnh sửa xong, lưu file robots.txt và upload lên server. Nếu sử dụng plugin WordPress, chỉ cần nhấn "Save Changes". Các thay đổi sẽ có hiệu lực ngay lập tức, mặc dù có thể mất vài giờ để các bot nhận biết và tuân thủ quy tắc mới.
Cách Kiểm Tra Và Xác Minh Hiệu Quả
Sau khi cấu hình robots.txt để chặn AI crawler, bạn cần kiểm tra để đảm bảo mọi thứ hoạt động đúng như mong đợi. Có nhiều công cụ và phương pháp để xác minh hiệu quả của cấu hình.
Kiểm Tra Cú Pháp Với Google Search Console
Google Search Console cung cấp công cụ "robots.txt Tester" giúp bạn kiểm tra cú pháp và xác minh các quy tắc. Truy cập Search Console, chọn "Cài đặt" > "robots.txt Tester" và nhập URL bạn muốn kiểm tra. Công cụ sẽ cho biết liệu bot có bị chặn hay không dựa trên quy tắc hiện tại.
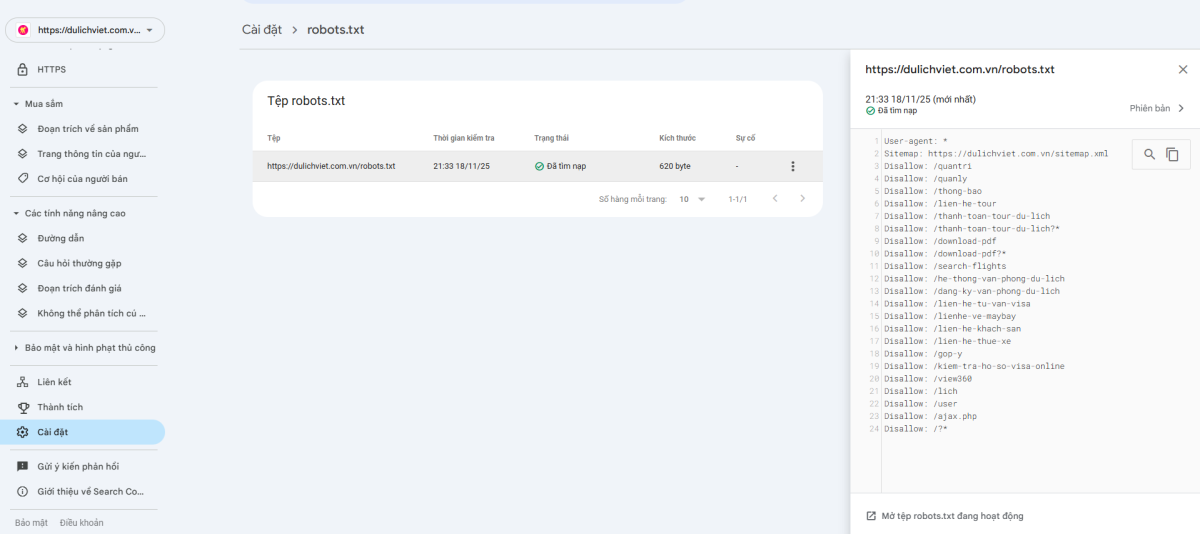
Mặc dù công cụ này chủ yếu dành cho Googlebot, nó vẫn hữu ích để kiểm tra cú pháp tổng thể và đảm bảo không có lỗi cơ bản trong file robots.txt. Các lỗi thường gặp bao gồm thiếu dấu cách, sai chính tả user-agent, hoặc cấu trúc không đúng.
Phân Tích Log Server
Cách hiệu quả nhất để xác minh là phân tích log truy cập của server. Tìm kiếm các user-agent như "GPTBot" hoặc "ClaudeBot" trong log để xem liệu chúng có còn truy cập sau khi bạn chặn hay không. Trên hosting sử dụng cPanel, bạn có thể truy cập "Raw Access Logs" để tải về và phân tích.
Sử dụng lệnh grep để lọc log nhanh chóng:
grep "GPTBot" access.log
Nếu không thấy bất kỳ entry nào sau vài ngày kể từ khi cấu hình, có thể kết luận rằng việc chặn đang hoạt động hiệu quả.
Sử Dụng Công Cụ Crawl Kiểm Tra
Screaming Frog SEO Spider là công cụ hữu ích để mô phỏng cách các bot quét website. Mặc dù nó không thể mô phỏng chính xác các AI crawler, bạn có thể dùng nó để kiểm tra xem các quy tắc robots.txt có áp dụng đúng cho các đường dẫn cụ thể hay không.
Theo Dõi Thường Xuyên
Việc kiểm soát AI crawler không phải là nhiệm vụ một lần. Các công ty AI liên tục phát triển bot mới hoặc thay đổi user-agent. Do đó, bạn nên:
- Kiểm tra log server định kỳ hàng tháng để phát hiện bot mới
- Cập nhật danh sách user-agent trong robots.txt khi có bot mới xuất hiện
- Theo dõi các thông báo chính thức từ các công ty AI về việc thay đổi bot
- Sử dụng công cụ monitoring để nhận cảnh báo khi phát hiện hoạt động bất thường
Lưu ý quan trọng là robots.txt chỉ là hướng dẫn, không phải lệnh bắt buộc. Các bot lớn như GPTBot và Google-Extended thường tuân thủ, nhưng không có gì đảm bảo 100%. Nếu cần bảo mật cao hơn, bạn nên kết hợp với các biện pháp khác như firewall hoặc rate limiting ở mức server.
Việc chặn GPTBot và các AI crawler khác bằng robots.txt là giải pháp đơn giản nhưng hiệu quả để bảo vệ nội dung website. Bằng cách hiểu rõ cách thức hoạt động và áp dụng đúng cấu hình, bạn có thể kiểm soát tốt hơn việc dữ liệu của mình được sử dụng như thế nào trong kỷ nguyên AI. Hãy thường xuyên cập nhật và theo dõi để đảm bảo chiến lược bảo vệ nội dung luôn hiệu quả trong năm 2025 và những năm tiếp theo.
Tham khảo thêm: Tìm hiểu về file robots.txt là gì để có cái nhìn tổng quan về công cụ này trong SEO.